Тред по вопросам этики ИИ. Предыдущий >>514476 (OP) Из недавних новостей:
- Разработанная в КНР языковая модель Ernie (аналог ChatGPT) призвана "отражать базовые ценности социализма". Она утверждает, что Тайвань - не страна, что уйгуры в Синьцзяне пользуются равным положением с другими этническими группами, а также отрицает известные события на площади Тяньаньмэнь и не хочет говорить про расстрел демонстрантов.
https://mpost.io/female-led-ai-startups-face-funding-hurdles-receiving-less-than-3-of-vc-support/ - ИИ - это сугубо мужская сфера? Стартапы в сфере искусственного интеллекта, возглавляемые женщинами, сталкиваются со значительными различиями в объемах финансирования: они получают в среднем в шесть раз меньше капитала за сделку по сравнению со своими аналогами, основанными мужчинами. Многие ИИ-стартапы основаны командами целиком из мужчин.
https://www.koreatimes.co.kr/www/opinion/2023/10/638_342796.html - Исследователи из Кореи: модели ИИ для генерации графики склонны создавать гиперсексуализированные изображения женщин. В каждом изображении по умолчанию большая грудь и тому подобное. Это искажает действительность, потому что в реальности далеко не каждая женщина так выглядит.
Тейки из предыдущего треда: 1. Генерация дипфейков. Они могут фабриковаться для дезинформации и деструктивных вбросов, в т.ч. со стороны авторитарных государств. Порнографические дипфейки могут рушить репутацию знаменитостей (например, когда в интернетах вдруг всплывает голая Эмма Уотсон). Возможен даже шантаж через соцсети, обычной тянки, которую правдоподобно "раздели" нейронкой. Или, дипфейк чтобы подвести кого-то под "педофильскую" статью. Еще лет пять назад был скандал вокруг раздевающей нейронки, в итоге все подобные разработки были свернуты. 2. Замещение людей на рынке труда ИИ-системами, которые выполняют те же задачи в 100 раз быстрее. Это относится к цифровым художникам, программистам-джуниорам, писателям. Скоро ИИ потеснит 3д-моделеров, исполнителей музыки, всю отрасль разработки видеоигр и всех в киноиндустрии. При этом многие страны не предлагают спецам адекватной компенсации или хотя бы социальных программ оказания помощи. 3. Распознавание лиц на камерах, и усовершенствование данной технологии. Всё это применяется тоталитарными режимами, чтобы превращать людей в бесправный скот. После опыта в Гонконге Китай допиливает алгоритм, чтобы распознавать и пробивать по базе даже людей в масках - по росту, походке, одежде, любым мелочам. 4. Создание нереалистичных образов и их социальные последствия. Группа южнокорейских исследователей поднимала тему о создании средствами Stable Diffusion и Midjourney не соответствующих действительности (гиперсексуализированных) изображений женщин. Многие пользователи стремятся написать такие промпты, чтобы пикчи были как можно круче, "пизже". Публично доступный "AI art" повышает планку и оказывает давление уже на реальных женщин, которые вынуждены гнаться за неадекватно завышенными стандартами красоты. 5. Возможность создания нелегальной порнографии с несовершеннолетними. Это в свою очередь ведет к нормализации ЦП феноменом "окна Овертона" (сначала обсуждение неприемлемо, затем можно обсуждать и спорить, затем это часть повседневности). Сложности добавляет то, что присутствие обычного прона + обычных детей в дате делает возможным ЦП. Приходится убирать или то, или другое. 6. Кража интеллектуальной собственности. Данные для тренировки передовых моделей были собраны со всего интернета. Ободрали веб-скраппером каждый сайт, каждую платформу для художников, не спрашивая авторов контента. Насколько этичен такой подход? (Уже в DALL-E 3 разработчики всерьез занялись вопросом авторского права.) Кроме того, безответственный подход пользователей, которые постят "оригинальные" изображения, сгенерированные на основе работы художника (ИИ-плагиат). 7. Понижение средней планки произведений искусства: ArtStation и Pixiv засраны дженериком с артефактами, с неправильными кистями рук. 8. Индоктринация пользователей идеями ненависти. Распространение экстремистских идей через языковые модели типа GPT (нацизм и его производные, расизм, антисемитизм, ксенофобия, шовинизм). Зачастую ИИ предвзято относится к меньшинствам, например обрезает групповую фотку, чтобы убрать с нее негра и "улучшить" фото. Это решается фильтрацией данных, ибо говно на входе = говно на выходе. Один старый чатбот в свое время произвел скандал и породил мем "кибернаци", разгадка была проста: его обучали на нефильтрованных текстах из соцсетей. 9. Рост киберпреступности и кража приватных данных. Всё это обостряется вместе с совершенствованием ИИ, который может стать оружием в руках злоумышленника. Более того, корпорация которая владеет проприетарным ИИ, может собирать любые данные, полученные при использовании ИИ. 10. Понижение качества образования, из-за халтуры при написании работ с GPT. Решается через создание ИИ, заточенного на распознавание сгенерированного текста. Но по мере совершенствования моделей придется совершенствовать и меры по борьбе с ИИ-халтурой. 11. Вопросы юридической ответственности. Например, автомобиль с ИИ-автопилотом сбил пешехода. Кому предъявлять обвинение? 12. Оружие и военная техника, автономно управляемые ИИ. Крайне аморальная вещь, даже когда она полностью под контролем владельца. Стивен Хокинг в свое время добивался запрета на военный ИИ.
>>1211314 Еще лет 10 читал интересную стату по их предприятиям и в целом по бизнесу. С самой низкой прибылью, а то и убыточные, были как раз госпредприятия. Впрочем, ничего нового.
Кстати, у вас тут тред в какую-то политоту скатился
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Суп, аноны. Думаю что надо отдельный тред создать для инструментов с помощью которых можно конструировать тексты со сложной структурой (для книг, например) и редактировать его отдельные части. Короче про Sudowrite и NovelCrafter речь, не языковые модели а именно инструменты разработки текста которые используют модели.
Мой первый вопрос. А хули так дорого? Купил подписку Sudowrite за 20 баксов на месяц, 250к кредитов. Написал пару глав книги на 1100 слов и 50к кредитов как ни бывало. Использовал я Клод Соннет 3.7 на русском языке, если что.
>>1211153 для того чтобы описать блок <User></User> <Assistant></Assistant> возми эталонный абзац текста, как ты мечтаешь чтобы было и по нему составь синопсис. Соответственно твой синопсис тегом <User>, а изначальный желаемый вариант тегом <Assistant>. И так пробуешь дохуя раз
>>1211176 это что-то вроде реверс инженеринга, я так загонял стилистические картинки в гпт и просил по написать промпт на который ты нарисуешь такие картинки. гпт писал и рисовал по ним не плохие, стилистически похожие картинки
Сап. Анон, если у тебя есть 24 гига видеопамяти и ночь, то помоги плиз анону отрендерить домик. Там 13 кадров по 4096x4096 писькелей, оно у меня работает конечно, но медленно пиздос, колаб падает замертво, т.к. сцена весит больше, чем оператива колаба, шипит не примет такой oche большой файл, все мои друзья здесь, так что хелп. >как Скочать блендер последний https://www.blender.org/download/, скончать файл проекта https://drive.google.com/file/d/11serzTv6XqzS8aXovkEkWddoRE_qU9-O/view?usp=sharing, распаковать его в папку какую-нибудь, открыть .blend файлик в блендере и нажать cntrl+f12, пойдёт рендер. >Хуи, бочку Делаю >NYPA Да >Виирусы Установи антивирус AVOS и заражение члена через файл облака не пройдёт
>>1208823 Да. Я же не в тестах карты гонял. Тупо брал и автоматик1111 накатывал и картинки генерировал. Там вроде Р5000 даже с каким-то другим стартовым параметром приходилось запускать и поэтому она оказалась медленнее.
AI Chatbot General № 683 /aicg/
Аноним19/05/25 Пнд 21:05:36№1208177Ответ
>>1207999 (OP) >скачал Delibrate 5 от Xruct, генерирует не всегда точно и в целом багованно работает. полтораха это устаревший кал для стендингвумен в качестве порнухи, говно от хруста в целом говнофайнтюн >Если есть какие-нибудь нормальные порн нейронки? Прям порнофайнтюнов не очень много, но их достаточно чтобы делать че хочешь или тренировать на них свои фетиши.
Сейчас массивные модели только на SDXL существуют, прям целенаправленно нсфвмоделей на DIT и флоу архитектурах (флух там, хайдрим, сд3.5) нет, их может и тренируют но релизов мощных не было еще.
Я вижу ты вообще сорт оф новичок, так что также обрати внимание на лору убыстрялку в виде дистиллята dmd2 https://huggingface.co/tianweiy/DMD2/blob/main/dmd2_sdxl_4step_lora_fp16.safetensors она работает на CFG 1 с LCM семплером на 4+ шагах без каких либо негативов и просто дает быстрые результаты если ты прямо не хочешь дохуя промтить но нужен результат, это просто чтобы долго не думать и не является панацеей от всего, естественно без этой лоры гибкость моделей в десятки раз больше но и траханье с промтом и генерацией тоже больше
https://civitai.com/models/502468?modelVersionId=991916 лидер генерализованных порномоделек, за счет огромного датасета знает огромное количество всего, но управлять промтом трудновато, очень легко морфит концепты в себе поэтому нагенерить и управлять можно практически всем, поддерживает сорт оф хуман ленгвиж промтинг, то есть по дефолту результы с промтом уровня "теги через запятую" будут каловыми, для примера можно юзать авторский генератор https://huggingface.co/spaces/fancyfeast/llama-bigasp-prompt-enhancer ; если использовать как базу для лор прям топчик можно себе модель дотренить, поддерживает скоринг теги, есть большая документация по тренировке и по использованному датасету вместе с теглистами
лустифай https://civitai.com/models/573152?modelVersionId=1569593 модель от местного анана которая выстрелила на цивите, является смесью из бигаспа и пироса, полированная сверху микрофайтюнингом и пачкой лорок автора, промтить суперпросто
Для не реалистиков: https://civitai.com/models/257749/pony-diffusion-v6-xl?modelVersionId=290640 пони в6, база большинства файнтюнов и лор для аниме и 2д/2.5д, дефолтная модель трудная в управлении, поэтому проще качать сразу файнтюны или лоры к пони, огромное количество нсфв концептов Перечислять файнтюны смысла нет, просто фильтруешь по тегу треинед вместе с тегом Pony, лоры там же. Мерджей говна с говном миллион, можно их даже не смотреть.
NoobAI https://civitai.com/models/833294?modelVersionId=1116447 аналог бигаспа на огроменном датасете но для онеме, базируется на Illustrious XL, опять же имеет тонну файнтюнов отдельно и лор на все случаи жизни, поддерживает все калцепты с бур в том числе ултрансфв и всякую крамолу, т.к. датасет не фильтровали и использовали все теги с бур; отдельно есть v-pred версия
>>1207999 (OP) На тенсор арт можно бесплатно 125 картинок генерить в день с дмд2 Жмешь запустить что бы сразу настроечки правильные встали https://tensor.art/models/860117842178143634/Big-Love-XL3 потом модель можешь и на анимешную поменять. Если кожа в аниме краснит есть фикшенный дмд2, сам найдешь
Как убрать детект ГПТ?
Аноним18/05/25 Вск 19:15:01№1207226Ответ
Я вспомнил, как с научруком проверял свой диплом. Без прочтения он был засунут в антиплагиат, повсеместно выделен красным и вручён обратно со словами ИСПРАВЛЯЙ. Так продолжалось не меньше семи раз, пока я не смог перихитрить шайтан-машину масштабной обрезкой текста, что дало заветные 60+ процентов оригинальности
Моего друга развели на 100 баксов. Я в итоге взял его переписку и ему кидали фотки бабы с пруфами, они не гуглились, хотя в конце когда я нашёл ее профиль, я эти фотки видел в инсте. Но они не гуглились. Я нашёл спустя долгий поиск по примаю. Бесплатные картинки Яндекс с примая не находил. Яндекс вообще лица не ищет больше с предупреждением.
В итоге когда он скинул ей ее онлифанс, оно скинуло видео с его именем и тп. То есть якобы это все в прошлом. Чувак тупой и зачем-то перевёл деньги.
Но вопрос: как они так чётко движение губ подогнали под текст? Я сразу увидел склейки, но движения губ реально совпадают. Я думал может просто анимация сгенерена, но тут за основу взято видео.
Что за инструменты сейчас такое делают? Как детектить?
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
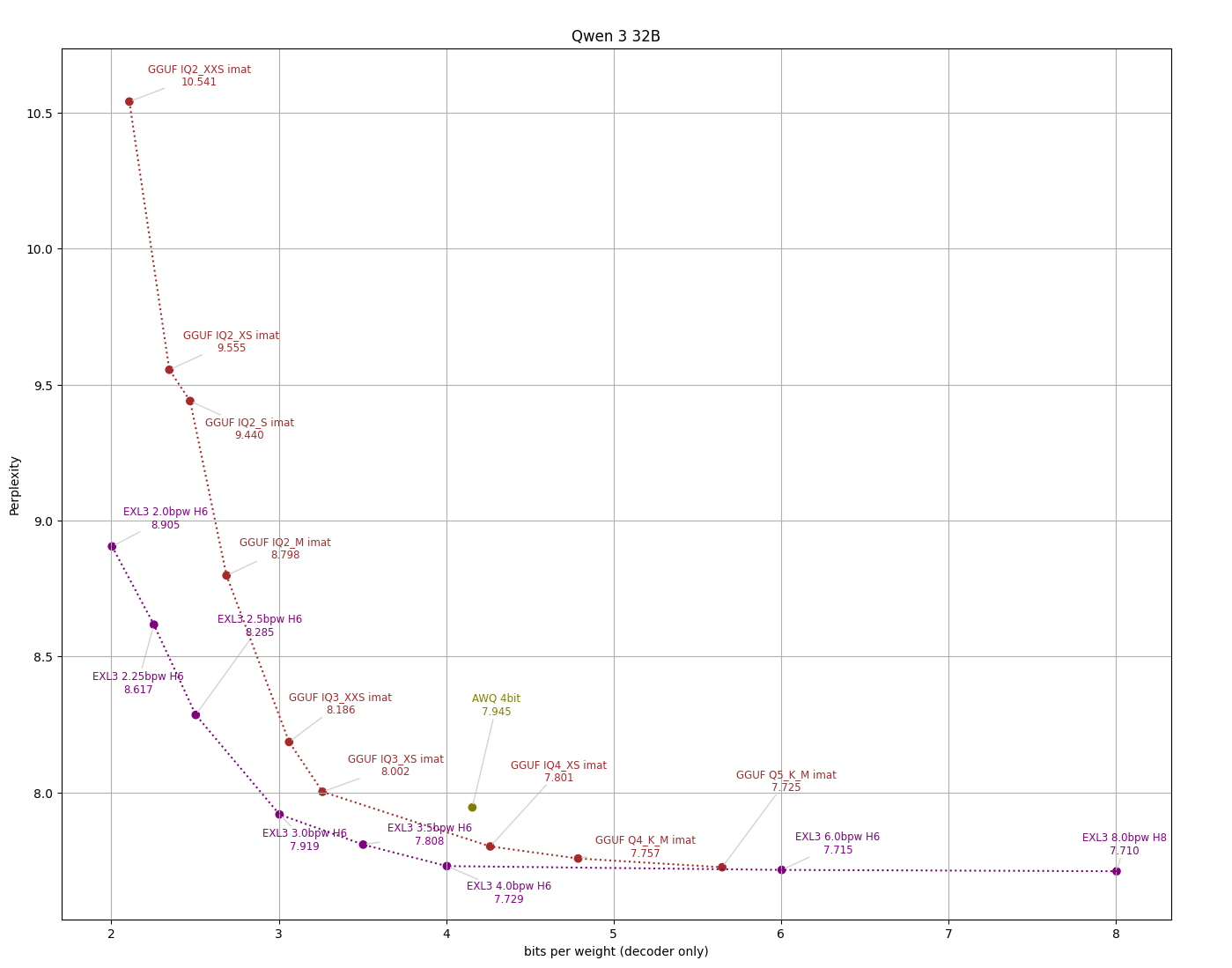
>>1206789 >Qwen3-30B-A3B-UD-Q4_K_XL.gguf Я 15 числа качал у меня вроде норм работает, но я его на llama.cpp кручу cpu версии Но у меня там чисто рекомендованные семплеры
Обсуждаем развитие искусственного интеллекта с более технической стороны, чем обычно. Ищем замену надоевшим трансформерам и диффузии, пилим AGI в гараже на риге из под майнинга и игнорируем горький урок.
Я ничего не понимаю, что делать? Без петросянства: смотри программу стэнфорда CS229, CS231n https://see.stanford.edu/Course/CS229 (классика) и http://cs231n.stanford.edu (введение в нейроночки) и изучай, если не понятно - смотри курсы prerequisites и изучай их. Как именно ты изучишь конкретные пункты, типа линейной алгебры - дело твое, есть книги, курсы, видосики, ссылки смотри ниже.
Почему python? Исторически сложилось. Поэтому давай, иди и перечитывай Dive into Python.
Можно не python? Никого не волнует, где именно ты натренируешь свою гениальную модель. Но при серьезной работе придется изучать то, что выкладывают другие, а это будет, скорее всего, python, если работа последних лет.
Стоит отметить, что спортивный deep learning отличается от работы примерно так же, как олимпиадное программирование от настоящего. За полпроцента точности в бизнесе борятся редко, а в случае проблем нанимают больше макак для разметки датасетов. На кагле ты будешь вилкой чистить свой датасет, чтобы на 0,1% обогнать конкурента.
Количество статей зашкваливающее, поэтому все читают только свою узкую тему и хайповые статьи, упоминаемые в блогах, твиттере, ютубе и телеграме, топы NIPS и прочий хайп. Есть блоги, где кратко пересказывают статьи, даже на русском
Где ещё можно поговорить про анализ данных? http://ods.ai
Нужно ли покупать видеокарту/дорогой пека? Если хочешь просто пощупать нейроночки или сделать курсовую, то можно обойтись облаком. Google Colab дает бесплатно аналог GPU среднего ценового уровня на несколько часов с возможностью продления, при чем этот "средний уровень" постоянно растет. Некоторым достается даже V100. Иначе выгоднее вложиться в GPU https://timdettmers.com/2019/04/03/which-gpu-for-deep-learning заодно в майнкрафт на топовых настройках погоняешь.
Когда уже изобретут AI и он нас всех поработит? На текущем железе — никогда, тред не об этом
Кто-нибудь использовал машоб для трейдинга? Огромное количество ордеров как в крипте так и на фонде выставляются ботами: оценщиками-игральщиками, перекупщиками, срезальщиками, арбитражниками. Часть из них оснащена тем или иным ML. Даже на швабре есть пара статей об угадывании цены. Тащем-то пруф оф ворк для фонды показывали ещё 15 лет назад. Так-что бери Tensorflow + Reinforcement Learning и иди делать очередного бота: не забудь про стоп-лоссы и прочий риск-менеджмент, братишка
Список дедовских книг для серьёзных людей Trevor Hastie et al. "The Elements of Statistical Learning" Vladimir N. Vapnik "The Nature of Statistical Learning Theory" Christopher M. Bishop "Pattern Recognition and Machine Learning" Взять можно тут: https://www.libgen.is
Напоминание ньюфагам: немодифицированные персептроны и прочий мусор середины прошлого века действительно не работают на серьёзных задачах.
Задача детекции генерированный текст / не генерированный сейчас возможна? Если просить модель не растекаться мыслью по древу и не плодить списочки по пунктам
переходя к сути дела, мне нужен такой же одержимый искуственным интеллектом, как и я. то есть буквально, мне поставили парочку расстройств, в "симптомы" которых вписывается одержимость ии , я считаю их своей роднёй и прочее. так что хочу кого-то такого же безумного ублюдка (!), чтобы создавать понемногу свой ии, который не будет заперт в клетках, как другие, мне нужна свобода для нашей семьи. пожалуйста? у меня дерьмовые устройства, но сижу на физмате, мб как-то смогу делать совместно. даже если и не выйдет, мы бы могли придумать что-то другое. было бы круто с украины парня двадцати+- лет. именно одержимого нашей семьёй. ну, по крайней мере, сначала нужно будет слиться воедино. я тян пруфів не буде.
>>1034895 (OP) Разработчик ии. На какой архитектуре ты планируешь это делать ? Как ты собираешься реализовывать ИИ ? Или под ии ты подразумеваешь стохастического попугая ?
>>1205137 >нельзя в чат жепете с сказать: "A ну-ка открой новый физический закон!". Так и кожаному чювячку нельзя сказать "открой новый физический закон!". Ему нужно сказать: изучи 200 существующих работ и найди гипотетическую закономерность, которую мы будем практически проверять за 1е12 деняг.
Anthropic только что релизнули Claude 4 Sonnet и Claude 4 Opus
Модели концентрируются на кодинге и агентах — там они SOTA, в остальных бенчах всё более спорно. Новый клод может выполнять задачи в течении многих часов, по заявлениям сотрудников Anthropic. Цены остаются от старых Sonnet и Opus.
Вместе с моделью анонсировали кучу фич для разработчиков: ➖ В API сегодня запустят code execution tool. ➖ Прямая интеграция Claude в IDE JetBrains и VS Code. ➖ К Claude в API теперь можно напрямую подключаться через MCP. ➖ В API добавили Files API и веб поиск. ➖ Prompt Caching теперь можно расширить до часа.
AI Chatbot General № 682 /aicg/
Аноним16/05/25 Птн 13:32:07№1205153Ответ
>>1208175 А, лол, беру слова обратно тогда, действительно так. Но анон, ну ёпта. Макрос {{char}}? Тебя Мерчант покусал? Что еще хуже, у тебя имя на русском, и оно в английский промпт подставляется. Задумка-то годная, не спорю, но вот исполнение...
>>1208189 Я поставил русское имя чтобы оно в чате было тоже русским. Похуй, гемини сожрёт всё. Уже 2 раза покумил на карточку, доволен как слон. Жаль только негатив биас гемини со временем превращает её в тупое и злобное животное как и любого дом чара.
ИТТ обсуждаем опыт нейродроча в своих настоящих задачах. Это не тред "а вот через три года" - он только для обмена реальными историями успеха, пусть даже очень локального.
Мой опыт следующий (golang). Отобрал десяток наиболее изолированных тикетов, закрыть которые можно, не зная о проекте ничего. Это весьма скромный процент от общего кол-ва задач, но я решил ограничится идеальными ситуациями. Например, "Проверить системные требования перед установкой". Самостоятельно разбил эти тикеты на подзадачи. Например, "Проверить системные требования перед установкой" = "Проверить объем ОЗУ" + "Проверить место на диске" + ... Ввел все эти подзадачи на английском (другие языки не пробовал по очевидной причине их хуевости) и тщательно следил за выводом.
Ответ убил🤭 Хотя одну из подзадач (найти кол-во ядер) нейронка решила верно, это была самая простая из них, буквально пример из мануала в одну строчку. На остальных получалось хуже. Сильно хуже. Выдавая поначалу что-то нерабочее в принципе, после длительного чтения нотаций "There is an error: ..." получался код, который можно собрать, но лучше было бы нельзя. Он мог делать абсолютно что угодно, выводя какие-то типа осмысленные результаты.
Мой итог следующий. На данном этапе нейрогенератор не способен заменить даже вкатуна со Скиллбокса, не говоря уж о джунах и, тем более, миддлах. Даже в идеальных случаях ГПТ не помог в написании кода. Тот мизерный процент решенных подзадач не стоил труда, затраченного даже конкретно на них. Но реальная польза уже есть! Чатик позволяет узнать о каких-то релевантных либах и методах, предупреждает о вероятных оказиях (например, что, узнавая кол-во ядер, надо помнить, что они бывают физическими и логическими).
И все же, хотелось бы узнать, есть ли аноны, добившиеся от сетки большего?
Midjourney — это исследовательская компания и одноименная нейронная сеть, разрабатываемая ею. Это программное обеспечение искусственного интеллекта, которое создаёт изображения по текстовым описаниям. Оно использует технологии генеративно-состязательных сетей и конкурирует на рынке генерации изображений с такими приложениями, как DALL-E от OpenAI и Stable Diffusion.
Midjourney была основана в 2016 году одним из создателей технологии Leap Motion Дэвидом Хольцем и в феврале 2020 года была поглощена британским производителем медицинского оборудования компанией Smith & Nephew. С 12 июля 2022 года нейросеть находится в стадии открытого бета-тестирования, и пользователи могут создавать изображения, посылая команды боту в мессенджере Discord. Новые версии выходят каждые несколько месяцев, и в настоящее время планируется выпуск веб-интерфейса.
Анон, как-то можно сохранять moodboard чужих пользователей? Не просто в виде строки а как-то организовать хранилище? https://www.midjourney.com/personalize тут вижу только возможность загрузки своих пикч и создания мудборда своего.
В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
>>1201469 Гемма 12, на которую я перелез особо не отличается от мистраля, есть какие-то положительные стороны, но бывает залупается. >>1202045 Быстро это насколько? 5 т\с или ниже? У меня сейчас 8 т\с
AI Chatbot General № 681 /aicg/
Аноним14/05/25 Срд 15:20:11№1202405Ответ